Originally posted: 2022-08-05. View source code for this page here.
Splink now includes Python and AWS Athena backends, in addition to Spark. It's easier to use, faster and more flexible, and can be used for close to real time linkage.
Two years ago, we introduced Splink, a Python library for data deduplication and linkage (entity resolution) at scale.

Since then, Splink has been used in government, the private sector, and academia to link and deduplicate huge datasets, some in excess of 100 million records, and it’s been downloaded over 3 million times.
We believe that it is now the fastest and most accurate free library for record linkage at scale.
We’ve learned a lot from our users, and we’ve just released version 3, which includes frequently requested features and tries to address some the biggest pain points.
- Splink 3 now offers support for Python and AWS Athena backends, in addition to Spark. Linking in Python is supported by the Python DuckDB package, which is capable of linking datasets of up to about 2 million records on a laptop.
- Small linkages can run 100x faster through use the new DuckDB backend, relative to Spark. It’s possible to link a dataset of a million records in under two minutes on a modern laptop.
- Close to real time linkage is possible, using the DuckDB backend, which could enable Splink to be embedded in search services.
- Interactive dashboards are now core Splink outputs.
- Splink 3 is written to be agnostic to the target SQL backend, meaning adding support for new backends is relatively straightforward.
- Linkage models are now simpler to estimate. Less code is needed, and the API is clearer. Splink now automatically combines parameter estimates from different model runs, significantly reducing the number of lines of code to estimate a full model.
- Linkages in Spark run significantly faster, and are less likely to result in out of memory errors or other scaling issues. Big data linkage in Athena runs significantly faster than Spark in some instances.
- Clustering of links to produce unique identifiers is now implemented in Splink, so does not require configuration of external dependencies like
graphframes. - A new documentation website brings together tutorials, topic guides, API documentation, and an interactive settings editor.
- An overhaul of all charting outputs makes them simpler, easier to read, and improves their labelling.
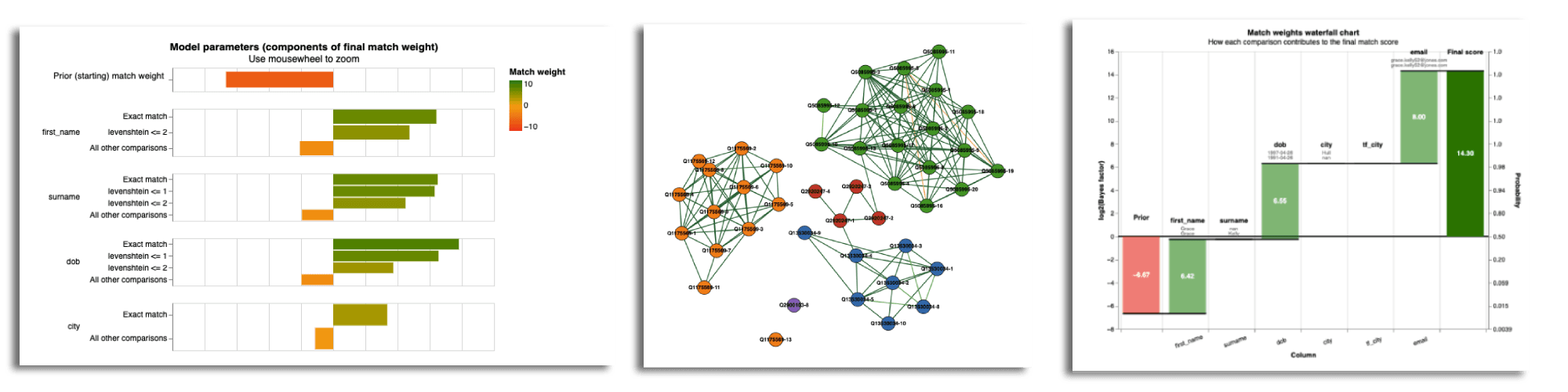
You can try out the library in a Jupyter notebook in Binder here. Note this is a small, free server, so don’t expect fast performance.
Please see our series of tutorials, an introductory video, and our interactive training materials on the underlying statistical theory.
We are grateful to all our users who have contributed and provided feedback. Please continue to do so by:
- Raising an issue if you’ve found a bug or would like to request a new feature
- Starting a discussion if you have questions about how to do something
- Raising a pull request if you’d like to fix a bug or add a feature
Or I’m @robinlinacre on Twitter.
We’d be particularly interested to work with anyone who’d like to add support for new SQL backends such as Postgres, Google BigQuery etc.